
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- items()
- glob
- CSS
- __len__
- View
- count()
- JS
- randrange()
- choice()
- shutil
- locals()
- HTML
- remove()
- inplace()
- shuffle()
- mro()
- decode()
- discard()
- Database
- MySqlDB
- MySQL
- 파이썬
- 오버라이딩
- fnmatch
- __getitem__
- __sub__
- __annotations__
- fileinput
- zipfile
- node.js
Archives
- Today
- Total
흰둥이는 코드를 짤 때 짖어 (왈!왈!왈!왈!왈!왈!왈!왈!왈!왈!왈!)
(파이썬) 파일 입출력 라이브러리 본문
728x90
반응형
1.파일 읽기 및 저장하기
1-1. fileinput
- 텍스트 파일을 읽고, 쓰고, 저장하는 기능을 편리하게 사용할 수 있도록 해주는 라이브러리
- 여러개의 파일을 읽어서 수정할 수 있음
In [1]:
import fileinput
import os
import glob
In [2]:
# 형재 경로 확인
os.getcwd()
Out[2]:
'C:\\LeeCoding\\Python\\Jupyter'In [3]:
# 디렉토리 내 파일 확인
os.listdir(os.getcwd())
Out[3]:
['.ipynb_checkpoints', '24 파일 입출력 라이브러리.ipynb', 'sample']
In [4]:
# 경로 설정
path = 'sample/'
In [5]:
# glob(): 해당 경로의 파일 이름을 리스트로 반환
glob.glob(os.path.join(path, '*.txt'))
Out[5]:
['sample\\새파일1.txt',
'sample\\새파일2.txt',
'sample\\새파일3.txt',
'sample\\새파일4.txt',
'sample\\새파일5.txt']
In [6]:
with fileinput.input(glob.glob(os.path.join(path, '*.txt'))) as f:
for line in f:
print(line)
1번째 라인입니다
2번째 줄입니다.
3번째 줄입니다.
4번째 라인입니다
5번째 줄입니다.
6번째 줄입니다.
7번째 라인입니다
8번째 줄입니다.
9번째 줄입니다.
10번째 라인입니다
11번째 줄입니다.
12번째 줄입니다.
13번째 라인입니다
14번째 줄입니다.
15번째 줄입니다.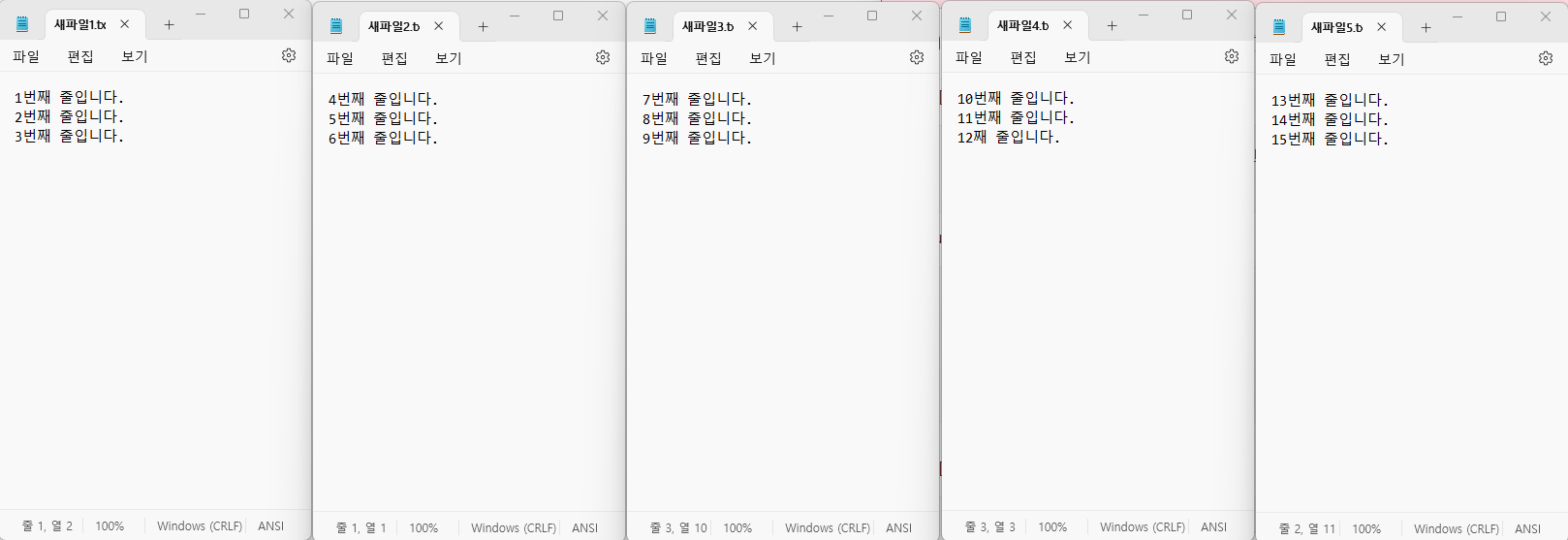
In [7]:
txt_files = glob.glob(os.path.join(path, '*.txt'))
In [8]:
print(txt_files)
['sample\\새파일1.txt', 'sample\\새파일2.txt', 'sample\\새파일3.txt', 'sample\\새파일4.txt', 'sample\\새파일5.txt']
In [9]:
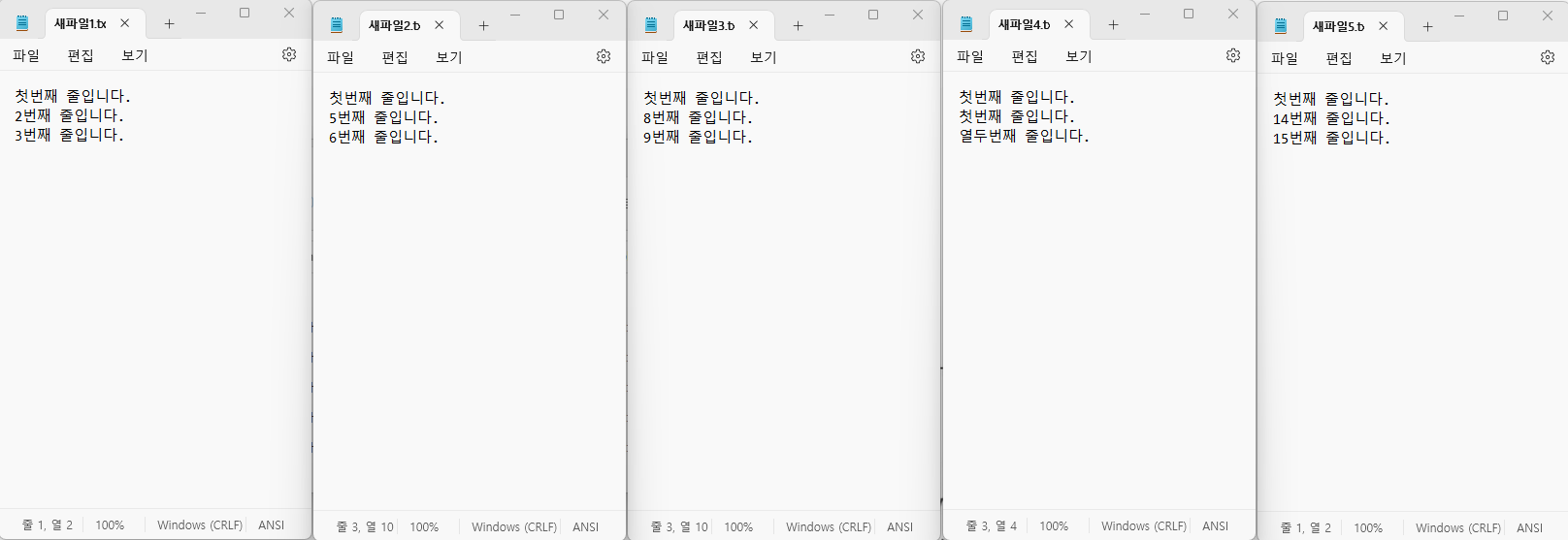
# 각파일의 첫번째 라인을 찾아 변경하기
with fileinput.input(txt_files, inplace=True) as f:
for line in f:
if f.isfirstline():
print('첫번째 라인입니다', end = '\n')
else:
print(line, end='')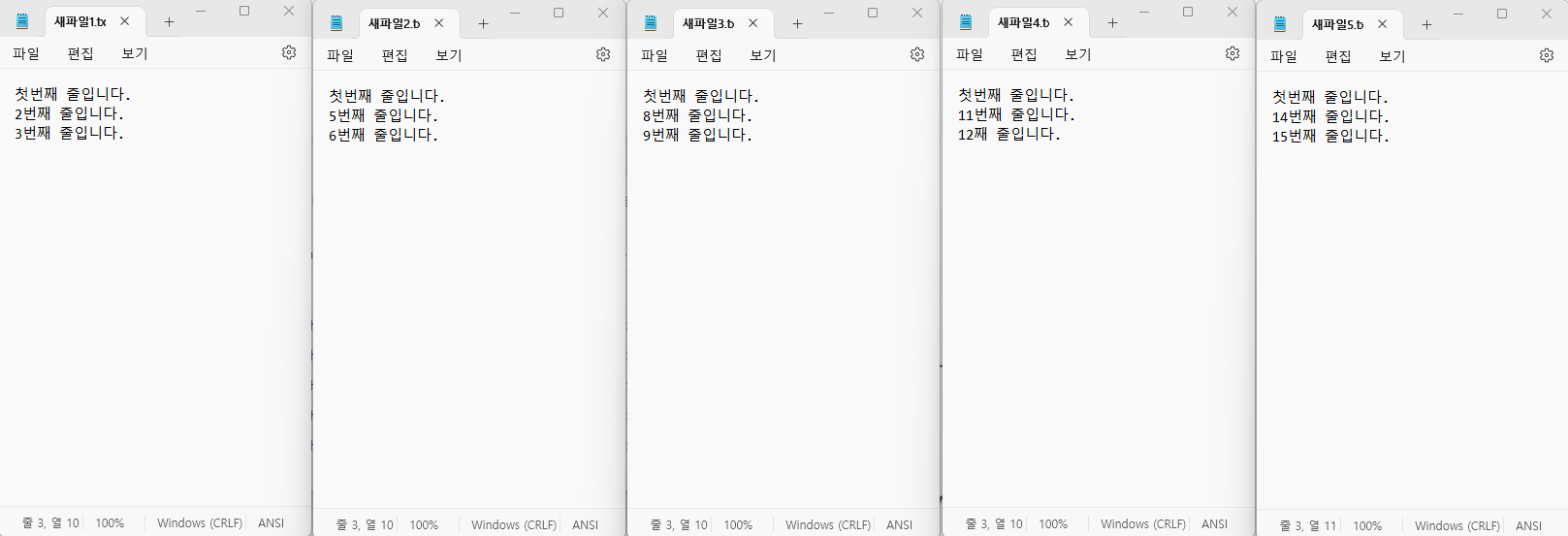
In [10]:
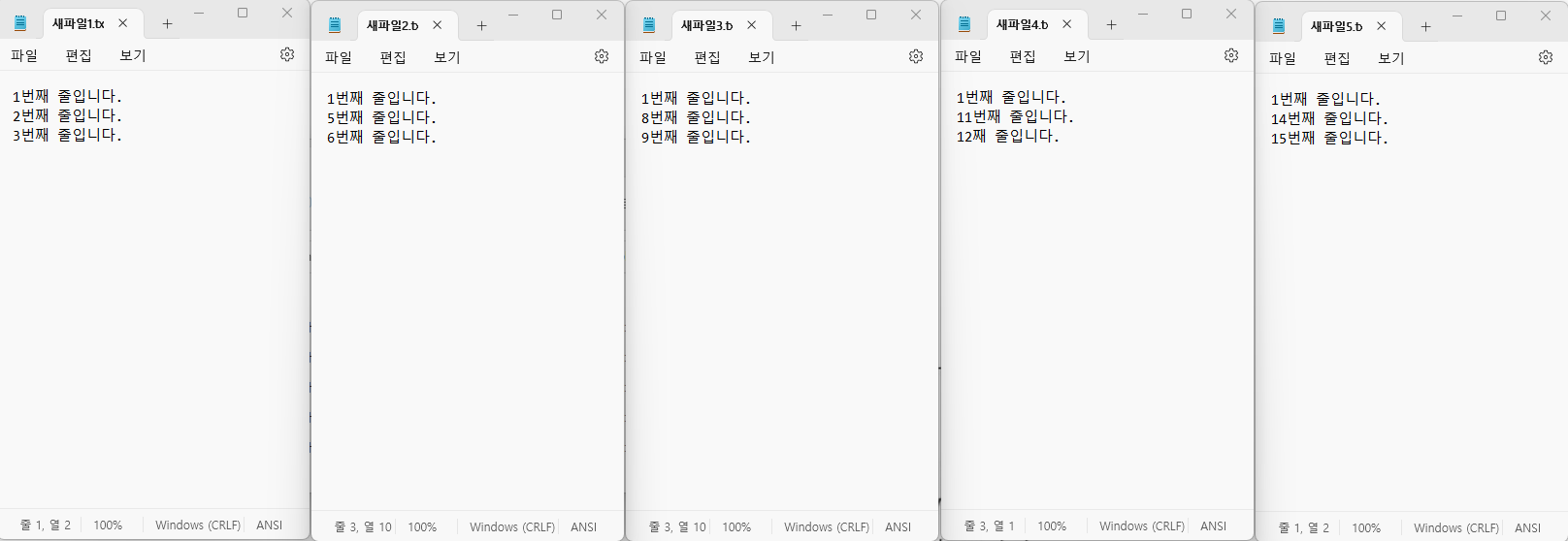
# 검색된 라인 변경하기
with fileinput.input(txt_files, inplace=True) as f:
for line in f:
if line == '첫번째 라인입니다\n':
print('1번째 라인입니다', end = '\n')
else:
print(line, end='')
In [12]:
# 키워드 포함 라인 변경하기
with fileinput.input(txt_files, inplace=True) as f:
for line in f:
if '1번째' in line:
print('첫번째 줄입니다.', end = '\n')
else:
print(line, end='')

In [13]:
# 텍스트 치환하기
with fileinput.input(txt_files, inplace=True) as f:
for line in f:
if '12번째' in line:
print(line.replace('12번째', '열두번째'), end = '')
else:
print(line, end='')
1-2. pickle
- 파이썬에서 사용하는 딕셔너리, 리스트, 클래스 등의 자료형을 변환 없이 그대로 파일로 저장하고 불러올 때 사용하는 모듈
In [14]:
import pickle
In [15]:
data = ['apple', 'banana', 'orange']
In [16]:
# 파일 저장
with open('list.pkl', 'wb') as f:
pickle.dump(data, f)


In [17]:
# 파일 읽기
with open('list.pkl', 'rb') as f:
data = pickle.load(f)
In [18]:
type(data)
Out[18]:
listIn [19]:
print(data)
['apple', 'banana', 'orange']
메모장에 보이는것은 깨져있지만 파이썬 쪽에서는 이상 없이 출력된다.
In [20]:
# 딕셔너리 저장
data = {}
data[1] = {'id':1, 'userid':'apple', 'name':'김사과', 'gender':'여자', 'age':20}
In [21]:
# 파일 저장
with open('dict.pkl', 'wb') as f:
pickle.dump(data, f)

In [22]:
# 파일 읽기
with open('dict.pkl', 'rb') as f:
data = pickle.load(f)
In [23]:
type(data)
Out[23]:
dictIn [24]:
print(data)
{1: {'id': 1, 'userid': 'apple', 'name': '김사과', 'gender': '여자', 'age': 20}}
2. 파일 찾기, 복사, 이동하기
2-1. 파일 확장자로 찾기
In [25]:
os.getcwd()
Out[25]:
'C:\\LeeCoding\\Python\\Jupyter'In [28]:
for filename in glob.glob('*.txt'):
print(filename)
주피터노트북.txt

In [29]:
# txt 파일 찾기 : 하위 경로
for filename in glob.glob('**/*.txt'):
print(filename)
sample\새파일1.txt
sample\새파일2.txt
sample\새파일3.txt
sample\새파일4.txt
sample\새파일5.txt
**/ 은 현재 파일위치에서 하위에 있는 파일경로를 의미한다.
In [31]:
# txt 파일 찾기 : 현재와 하위 경로 모두 포함
for filename in glob.glob('**/*.txt', recursive=True):
print(filename)
주피터노트북.txt
sample\새파일1.txt
sample\새파일2.txt
sample\새파일3.txt
sample\새파일4.txt
sample\새파일5.txt
recursive=True 를 설정 할경우 현재 경로까지 포함하여 준다.
In [32]:
# 파일명 글자수로 찾기
for filename in glob.glob('????.*', recursive=True): # 글자수 4개
print(filename)
dict.pkl
list.pkl
'?' 개수가 파일명 글자수를 나타난다.
In [33]:
for filename in glob.glob('??????.*', recursive=True): # 글자수 6개
print(filename)
주피터노트북.txt
In [36]:
# 문자열 패턴 포함 파일명 찾기
for filename in glob.glob('[a-z][a-z][a-z][a-z].*', recursive=True): # 알파벳 글자수 4개
print(filename)
dict.pkl
list.pkl
[]안에 문자열의 범위를 지정해 줄 수 있다.
In [37]:
for filename in glob.glob('**/새파일*.*', recursive=True):
print(filename)
sample\새파일1.txt
sample\새파일2.txt
sample\새파일3.txt
sample\새파일4.txt
sample\새파일5.txt
In [38]:
for filename in glob.glob('**/*프로젝트*.*', recursive=True):
print(filename)
project\25. 프로젝트 실습.ipynb
project\프로젝트 개요.txt

'*'과 '*'사이에 적은 문자열이 포함된 모든 파일을 찾는다.
2-2. fnmatch
- glob과 동일하게 특정한 패턴을 따르는 파일명을 찾아주는 모듈
- 파일명 매칭 여부를 True, False 형태로 반환하기 때문에 os.listdir() 함수와 함께 사용
In [39]:
import fnmatch
In [41]:
# 파일명은 '새' 시작하고 확장명은 .txt를 검색
# 확장자를 제외한 파일명의 길이는 4개이며, 파일명의 마지막 문자는 숫자임
for filename in os.listdir('./sample'):
if fnmatch.fnmatch(filename, '새??[0-9].txt'):
print(filename)
새파일1.txt
새파일2.txt
새파일3.txt
새파일4.txt
새파일5.txt
2-3. shutil
- 파일을 복사하거나 이동할 때 사용하는 내장 모듈
In [42]:
import shutil
In [43]:
# 파일 복사하기
shutil.copy('./sample/새파일1.txt', './sample/새파일1_복사본.txt')
Out[43]:
'./sample/새파일1_복사본.txt'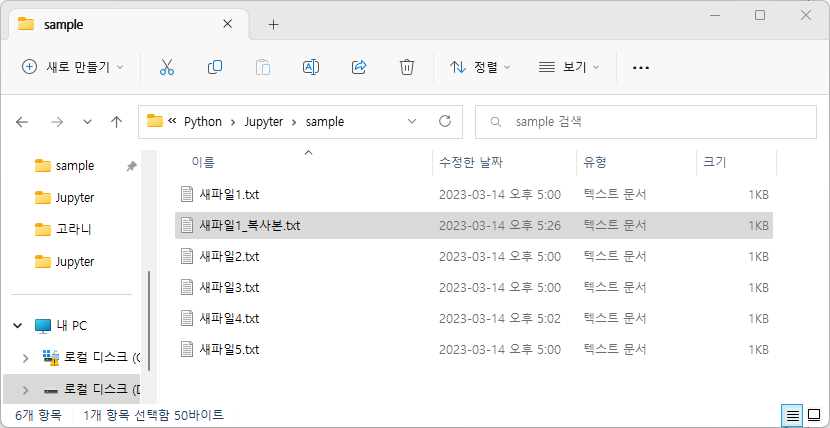
In [46]:
# 파일 이동하기
shutil.move('./sample/새파일1_복사본.txt', './새파일1_복사본.txt')
Out[46]:
'새파일1_복사본.txt'

In [47]:
# 확장명 바꾸기
shutil.move('./새파일1_복사본.txt', './새파일1_복사본.py')
Out[47]:
'./새파일1_복사본.py'
In [48]:
# 확장명 바꾸기
shutil.move('./새파일1_복사본.py', './새파일1_복사본.txt')
Out[48]:
'./새파일1_복사본.txt'3. 파일 압축
3-1. 데이터 압축
- 대용량 데이터 및 대량의 파일을 전송 시, 전송 속도가 느리며 전송 문제가 발생할 가능성이 매우 높음
- 데이터 압축의 종류
- 손실 압축: 사람이 눈치채지 못할 수준의 정보만 버리고 압축하는 방법
- 무손실 압축: 데이터 손실이 전혀 없는 압축
- 압축률: 압축된 자료량(압축된 데이터 크기) / 원시 자료량(원래 데이터 크기)
- 다양한 압축 알고리즘에 따라 압축 성능 및 시간이 좌우됨
- 압축: 인코딩(Encoding)
- 압측 해제: 디코딩(Decoding)
3-2. zlib
- 데이터를 압축하거나 해제할 때 사용하는 모듈
- compress()와 decompress() 함수로 문자열을 압축하거나 해제
- 데이터 크기를 줄여서 전송이 필요한 경우 사용
In [56]:
import zlib
In [57]:
data = 'Hello Python!' * 10000
In [58]:
data
Out[58]:
'Hello Python!Hello Python!Hello Python!Hello Python!Hello Python! ... Hello Python!Hello Python!'In [59]:
print(len(data)) # 130000 byte
130000
In [61]:
compress_data = zlib.compress(data.encode(encoding='utf-8'))
print(len(compress_data)) # 293 byte
293
compress()로 압축을 하며 encode()로 변환해준다.
In [62]:
compress_data
Out[62]:
b'x\x9c\xed\xc71\r\x00 \x0c\x000+\xe0f\'&H8\x16\xf6\xf0\xe0\x1e\x1f\xa4\xfd\x1a3\xb3\xda\xb8g\xd5\xee!"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""?\xe6\x01le79'In [63]:
org_data = zlib.decompress(compress_data).decode('utf-8')
print(len(org_data))
130000
decompress()로 압축 해제하며 decode()로 변환해준다.
3-3. gzip
- 파일을 압축하거나 해제할 때 사욯하는 모듈
- 내부적으로 zlib 알고리즘을 사용
In [65]:
import gzip
In [66]:
with open('org_data.txt', 'w') as f:
f.write(data)
In [67]:
# gzip으로 압축
with gzip.open('compressed.txt.gz', 'wb') as f:
f.write(data.encode('utf-8'))

In [68]:
# gzip 압축 해제
with gzip.open('compressed.txt.gz', 'rb') as f:
org_data = f.read().decode('utf-8')
In [70]:
print(len(org_data))
130000
3-4. zipfile
- 여러개 파일을 zip 확장자로 합쳐서 압축할 때 사용하는 모듈
In [71]:
import zipfile
In [73]:
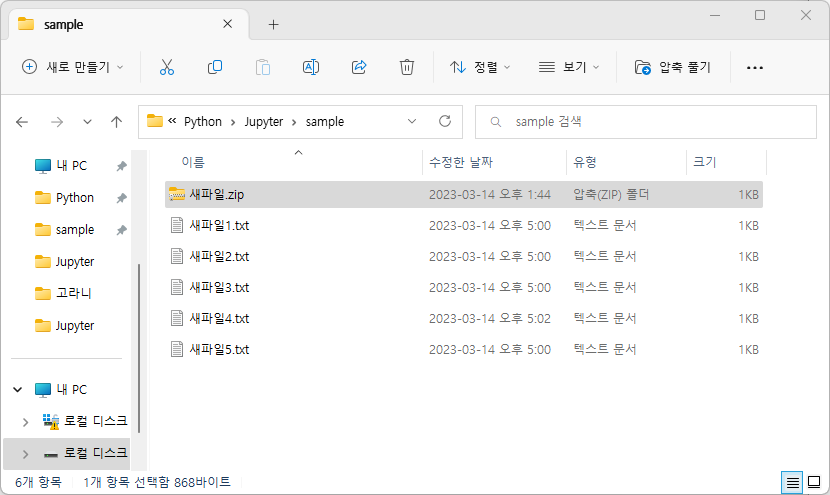
# 파일 합치고 압축하기
with zipfile.ZipFile('./sample/새파일.zip', 'w') as myzip:
myzip.write('./sample/새파일1.txt')
myzip.write('./sample/새파일2.txt')
myzip.write('./sample/새파일3.txt')
myzip.write('./sample/새파일4.txt')
myzip.write('./sample/새파일5.txt')
In [74]:
# 압축 해제하기
with zipfile.ZipFile('./sample/새파일.zip') as myzip:
myzip.extractall()
3-5. tarfile
- 여러개 파일을 tar 확장자로 합쳐서 압축할 때 사용하는 모듈
In [75]:
import tarfile
In [76]:
# 파일 합치고 압축하기
with tarfile.open('./sample/새파일.tar', 'w') as mytar:
mytar.add('./sample/새파일1.txt')
mytar.add('./sample/새파일2.txt')
mytar.add('./sample/새파일3.txt')
mytar.add('./sample/새파일4.txt')
mytar.add('./sample/새파일5.txt')

In [78]:
# 압축 해제하기
with tarfile.open('./sample/새파일.tar') as mytar:
mytar.extractall()
728x90
반응형
'파이썬 기초' 카테고리의 다른 글
| (파이썬) DAO, DTO, VO 와 MVC 패턴 (0) | 2023.03.21 |
|---|---|
| (파이썬) 폴더 관리 프로그램 실습 (0) | 2023.03.14 |
| (파이썬) 변수 타입 어노테이션 (0) | 2023.03.13 |
| (파이썬) 클로저와 데코레이터 (0) | 2023.03.13 |
| (파이썬) 파일 입출력 (0) | 2023.03.13 |
'파이썬 기초' Related Articles
more




Comments